海量数据的二度人脉挖掘算法(Hadoop 实现)
最近做了一个项目,要求找出二度人脉的一些关系,就好似新浪微博的“你可能感兴趣的人” 中,间接关注推荐;简单描述:即你关注的人中有N个人同时都关注了 XXX 。
在程序的实现上,其实我们要找的是:若 User1 follow了10个人 {User3,User4,User5,... ,User12}记为集合UF1,那么 UF1中的这些人,他们也有follow的集合,分别是记为: UF3(User3 follow的人),UF4,UF5,...,UF12;而在这些集合肯定会有交集,而由最多集合求交产生的交集,就是我们要找的:感兴趣的人。
我在网上找了些,关于二度人脉算法的实现,大部分无非是通过广度搜索算法来查找,犹豫深度已经明确了2以内;这个算法其实很简单,***步找到你关注的人;第二步找到这些人关注的人,***找出第二步结果中出现频率***的一个或多个人,即完成。
但如果有***别的用户,那在运算时,就肯定会把这些用户的follow 关系放到内存中,计算的时候依次查找;先说明下我没有明确的诊断对比,这样做的效果一定没 基于hadoop实现的好;只是自己,想用hadoop实现下,最近也在学;若有不足的地方还请指点。
首先,我的初始数据是文件,每一行为一个follow 关系 ida+‘ ’+idb;表示 ida follow idb。其次,用了2个Map/Reduce任务。
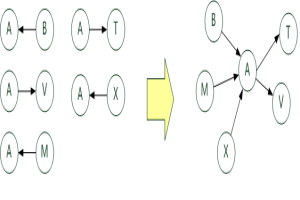
Map/Reduce 1:找出 任意一个用户 的 follow 集合与 被 follow 的集合。如图所示:
代码如下:
Map任务: 输出时 key :间接者 A 的ID ,value:follow 的人的ID 或 被follow的人的ID
- publicvoidmap(Textkey,IntWritablevalues,Contextcontext)throwsIOException,InterruptedException{
- intvalue=values.get();
- //切分出两个用户id
- String[]_key=Separator.CONNECTORS_Pattern.split(key.toString());
- if(_key.length==2){
- //"f"前缀表示follow;"b"前缀表示被follow
- context.write(newText(_key[0]),newText("f"+_key[1]));
- context.write(newText(_key[1]),newText("b"+_key[0]));
- }
- }
Reduce任务: 输出时 key :间接者 A 的ID , value为 两个String,***个而follow的所有人(用分割符分割),第二个为 被follow的人(同样分割)
- protectedvoidreduce(Textkey,Iterable<TextPair>pairs,Contextcontext)
- throwsIOException,InterruptedException{
- StringBuilderfirst_follow=newStringBuilder();
- StringBuildersecond_befollow=newStringBuilder();
- for(TextPairpair:pairs){
- Stringid=pair.getFirst().toString();
- Stringvalue=pair.getSecond().toString();
- if(id.startsWith("f")){
- first_follow.append(id.substring(1)).append(Separator.TABLE_String);
- }elseif(id.startsWith("b")){
- second_befollow.append(id.substring(1)).append(Separator.TABLE_String);
- }
- }
- context.write(key,newTextPair(first_follow.toString(),second_befollow.toString()));
- }
其中Separator.TABLE_String为自定义的分隔符;TextPair为自定义的 Writable 类,让一个key可以对应两个value,且这两个value可区分。
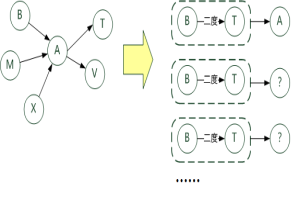
Map/Reduce 2:在上一步关系中,若B follow A,而 A follow T ,则可以得出 T 为 B 的二度人脉,且 间接者为A ,于是找出 相同二度人脉的不同间接人。如图所示:
代码如下:
Map 任务:输出时 key 为 由两个String 记录的ID表示的 二度人脉关系,value 为 这个二度关系产生的间接人的ID
- publicvoidmap(Textkey,TextPairvalues,Contextcontext)throwsIOException,InterruptedException{
- Map<String,String>first_follow=newHashMap<String,String>();
- Map<String,String>second_befollow=newHashMap<String,String>();
- String_key=key.toString();
- String[]follow=values.getFirst().toString().split(Separator.TABLE_String);
- String[]second=values.getSecond().toString().split(Separator.TABLE_String);
- for(Stringsf:follow){
- first_follow.put(sf,_key);
- }
- for(Stringss:second){
- second_befollow.put(ss,_key);
- }
- for(Entry<String,String>f:first_follow.entrySet()){
- for(Entry<String,String>b:second_befollow.entrySet()){
- context.write(newTextPair(f.getKey(),b.getKey()),newText(key));
- }
- }
- }
Reduce任务:输出时 key 仍然为二度人脉关系, value 为所有间接人 的ID以逗号分割。
- protectedvoidreduce(TextPairkey,Iterable<Text>values,Contextcontext)
- throwsIOException,InterruptedException{
- StringBuilderresutl=newStringBuilder();
- for(Texttext:values){
- resutl.append(text.toString()).append(",");
- }
- context.write(key,newText(resutl.toString()));
- }
到这步,二度人脉关系基本已经挖掘出来,后续的处理就很简单了,当然也基于二度人脉挖掘三度,四度:)
原文链接:http://my.oschina.net/BreathL/blog/75112