基于Hadoop云盘系统3:小文件存储优化
一、概述
首先明确概念,这里的小文件是指小于HDFS系统Block大小的文件(默认64M),如果使用HDFS存储大量的小文件,将会是一场灾难,这取决于HDFS的实现机制和框架结构,每一个存储在HDFS中的文件、目录和块映射为一个对象存储在NameNode服务器内存中,通常占用150个字节。如果有1千万个文件,就需要消耗大约3G的内存空间。如果是10亿个文件呢,简直不可想象。这里需要特别说明的是,每一个小于Block大小的文件,存储是实际占用的存储空间仍然是实际的文件大小,而不是整个block大小。
为解决小文件的存储Hadoop自身提供了两种机制来解决相关的问题,包括HAR和SequeueFile,这两种方式在某些方面解决了本层面的问题,单仍然存在着各自的不足。下文讲详细说明。
二、Hadoop HAR
Hadoop Archives(HAR files) ,这个特性从Hadoop 0.18.0版本就已经引入了,他可以将众多小文件打包成一个大文件进行存储,并且打包后原来的文件仍然可以通过Map-reduce进行操作,打包后的文件由索引和存储两大部分组成,索引部分记录了原有的目录结构和文件状态。其原理如下图所示: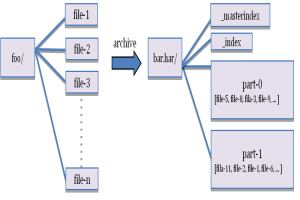
缺点:
1.HAR 方式虽然能够实现NameNode内存空间的优化,但是他是一个人工干预的过程,同时他既不能够支持自动删除原小文件,也不支持追加操作,当有新文件进来以后,需要重新打包。
2.HAR files一旦创建就不能修改,要做增加和修改文件必须重新打包。事实上,这对那些写后便不能改的文件来说不是问题,因为它们可以定期成批归档,比如每日或每周。
3.HAR files目前还不支持文档压缩。
三、SequeuesFile
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0版本开始中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩、文件级、块级别)。其存储结构如下图所示:

示例代码如下所示:
- privatestaticvoidwriteTest(FileSystemfs,intcount,intseed,Pathfile,
- CompressionTypecompressionType,CompressionCodeccodec)
- throwsIOException{
- fs.delete(file,true);
- LOG.info("creating"+count+"recordswith"+compressionType+
- "compression");
- //指明压缩方式
- SequenceFile.Writerwriter=
- SequenceFile.createWriter(fs,conf,file,
- RandomDatum.class,RandomDatum.class,compressionType,codec);
- RandomDatum.Generatorgenerator=newRandomDatum.Generator(seed);
- for(inti=0;i<count;i++){
- generator.next();
- //keyh
- RandomDatumkey=generator.getKey();
- //value
- RandomDatumvalue=generator.getValue();
- /追加写入
- writer.append(key,value);
- }
- writer.close();
- }
缺点:
目前为止只发现其Java版本API支持,未在其他开发接口中发现相关版本的实现,尤其是LibHDFS和thrift接口中,可能真是C++阵营狂热支持者的一个悲剧。
四、Hbase
如果你需要处理大量的小文件,并且依赖于特定的访问模式,可以采用其他的方式,比如Hbase。Hbase以MapFiles存储文件,并支持Map/Reduce格式流数据分析。对于大量小文件的处理,也不失为一种好的选择。
原文链接:http://www.cnblogs.com/hadoopdev/archive/2013/03/08/2950121.html
【编辑推荐】
- 基于Hadoop云盘系统1:上传和下载效率优化
- 基于Hadoop云盘系统2:HDFS文件访问控制
- 分布式文件系统HDFS设计
- 分布式文件系统HDFS中Block介绍
- HBase设计:看上去很美
